
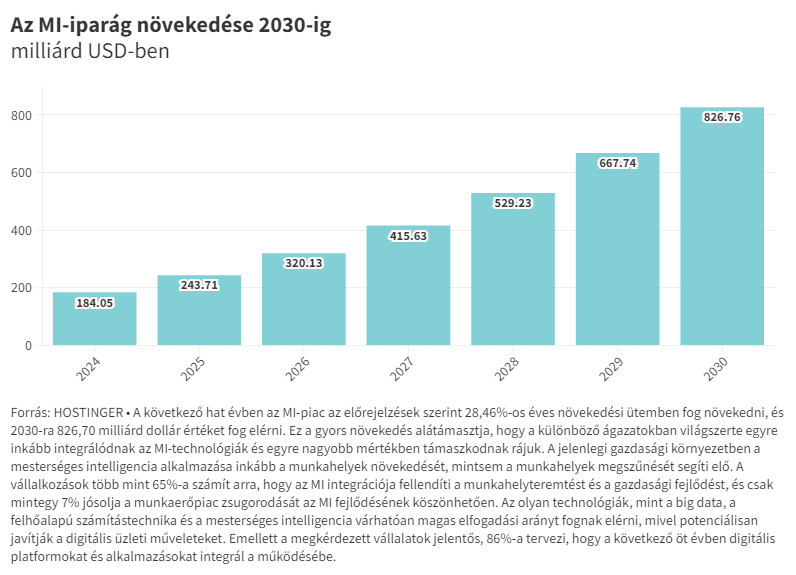
A mesterséges intelligencia (MI) jött, látott és úgy tűnik győzött, bármennyire is utálják sokan. Az elmúlt években rengeteg nóvumot láttunk ezen a területen a nagy nyelvi modellek kapcsán. Az OpenAI megoldása mellett megjelent az Anthropic Claude, a Meta Llama és a Google Geminije is. Lassan már szinte mindenki fejleszt saját MI-t magának. Egy dolog nem tagadható le, idén a hangsúly már az alkalmazási rétegre terelődött. Persze felvetődik a kérdés, hogy ezek csupán korai kísérletek voltak vagy új megoldások előtt nyitják meg az utat?
A hálózati hatások akkor jelentkeznek, amikor egy-egy szolgáltatás vagy termék értéke megnövekszik, amikor egyre többen használják azt. Ez az elv tulajdonképpen a piaci dominancia, a fenntartható növekedés és az innováció sarokkövévé vált mára az ICT-iparban. Érdemes tehát egy kicsit megvizsgálni, hogy miért olyan értékes ez a hálózati hatás, hogyan haladja meg az egykor annyira kötelező funkció központúságot és miért szolgálja a vállalatok hosszú távú sikerét is.



A hálózati hatások tulajdonképpen azt a jelenséget fedik le, amikor egy-egy szolgáltatás vagy termék értéktöbbletet ér el (vagy nyer), ha egyre több ember használja. Ez a koncepció különböző formában jelenhet meg. Így lehet közvetlen hálózati hatásokról beszélni; amikor is minden egyes felhasználó maga is értéket ad át más felhasználónak (ilyenek az üzenetküldő alkalmazások). De természetesen közvetett hálózati hatásokról is; amikor a megnövekedett használat vezet előnyökhöz egyes kiegészítő termékekben és szolgáltatásokban. (Utóbbi helyzetre példa az alkalmazások nagyobb elérhetősége egy okostelefon-platformon.)
A hálózati hatások lényege az önmagát erősítő körforgás kialakításában rejlik. Vagyis: ahogy egyre több felhasználó kerül bele a körbe, úgy nő folyamatosan magának a hálózatnak is az értéke. Ez pedig még több felhasználót vonz magához így a jövőben.
Az egész nem más, mint egy szoftver
Mielőtt mélyebbre merülnénk a témában, érdemes tisztázni, hogy a mai MI-forradalom tulajdonképpen nem más, mint a szoftverek új evolúciója. Ma a szoftver viszont önmagában csak egy árucikk, és nem védhető könnyedén. A legsikeresebb szoftvercégek manapság csupán csak egy maroknyi mechanizmusra támaszkodnak a védhetőségük megteremtéséhez. Ezek a méretgazdaságosság, az átállási költségek, és ami nem kerülhető ki sehogy sem, mint láttuk és egyben a legfontosabb, a hálózati hatások.
A leglátványosabb gazdasági eltérés egy MI-vállalat és egy hagyományos szoftvercég között a határköltségeiben rejlik. Vagyis, hogy mennyibe is kerül egy termék további fejlesztésének költségében egy-egy új ügyfél „előállítása”. A ma általunk használt szoftverek (a Windows 11 például) határköltségei tulajdonképpen nem léteztek, hiszen ha egy terméket egyszer kifejlesztettek végtelen számú „példányt” lehetett belőle gyártani az új ügyfelek számára. Nem titok, az internet megjelenése ezt még hatékonyabbá tette, hiszen megkönnyítette a felhasználók számára, hogy hozzá is férjenek eme termékekhez. Ugyan az összes ügyfelünk kiszolgálása okoz némi többletköltséget, az adattárolás és a számítási költségek is azért megjelennek a folyamatban, de ezek a bevételek százalékában kifejezve általában soha nem jelentősek (gondoljunk csak a Google-ra).
A mesterséges intelligenciával foglalkozó mai új cégeknek viszont már eleve komoly határköltségei vannak. Hiszen a modellek képzése, a számítási költségeik hatalmas összegekre rúgnak. Egy kurrens modell kiképzése több tízmilliós nagyságrendű előzetes befektetést igényel. Arról nem is beszélve, hogy egy nagy nyelvi modellhez (LLM) egy-egy terméken keresztül intézett egyszerű lekérdezés (ChatGPT) tízszer többe kerül, mint egy „mezei” Google-féle kulcsszavas keresés. (Mindez a képzési költségei nélkül is így van.) Ez a dinamika viszont már egy másfajta méretgazdaságot eredményez az alapmodellek szintjén is. Vagyis az LLM-ek működtetésének és képzésének magas költségei egyfajta belépési korlátot jelentenek az új versenytársak számára. Nézzük meg, hogyan érvényesülnek ezek a mesterséges intelligencia-alkalmazások az internet elmúlt három évtizedének terminológiáit kölcsönözve.
MI 1.0
Közvetlen interakciót tesznek lehetővé a felhasználó és az MI-termék, azaz egy szoftver között. Ide tartoznak az olyan íróasszisztensek, mint a Quillbot, az olyan generátorok, mint a Lensa. Ezek képviselik az MI-alkalmazások legkorábbi hullámát az alapmodellek megjelenése után. Ezt a kategóriát MI 1.0-nak nevezzük, mivel a felhasználói közvetlenül lépnek kapcsolatba a mesterséges intelligenciával, hasonlóan a Web 1.0-hoz, ahol csak az információkhoz férnek hozzá.
Itt nincs lehetőség hálózati hatások kialakulására. Ezek akkor jelentkeznek, ha egy felhasználó hozzáadása növeli a termék értékét az összes többi számára: többszereplős, azaz két vagy több felhasználó közötti interakcióra lenne szükség. A kölcsönhatások itt egyszemélyesek, azaz a felhasználók csak a szoftverrel lépnek kapcsolatba.
MI 1.5
Az MI-alkalmazásoknak van egy másik kategóriája is, ahol a termék egy kicsit több, mint „tiszta szoftver”. Ehelyett a felhasználók egy MI által generált tartalmat hoznak létre, melyet aztán más felhasználók számára is felkínálhatnak. Lényeges, hogy a mesterséges intelligencia által generált tartalom létrehozásának folyamata „súrlódásmentes” legyen, és mindössze néhány kattintást vagy egyszerű kérést igényeljen.
A character.ai egy remek példa erre, ahol egy új bot létrehozása percekbe telik csupán. Az olyan MI dalgenerátorok, mint a Suno és az Udio szintén jól reprezentálják ezt a fázist, ahol a felhasználók MI által generált dalokat hoznak létre, melyeket majd mások is felfedezhetnek.
MI 2.0
Hogyan lehet tehát valódi, értelmes hálózati hatásokat létrehozni egy MI-alkalmazással? Az eddig elmondottak alapján az applikációnak olyan többjátékos interakcióval kell(ene) rendelkeznie, mely sokkal többet jelent, mint az MI által generált, egy másik felhasználó által létrehozott kimenet. Ezek az alkalmazások a mesterséges intelligenciát olyan többszereplős interakció lehetővé tételére használják, mely korábban még lehetetlen volt.
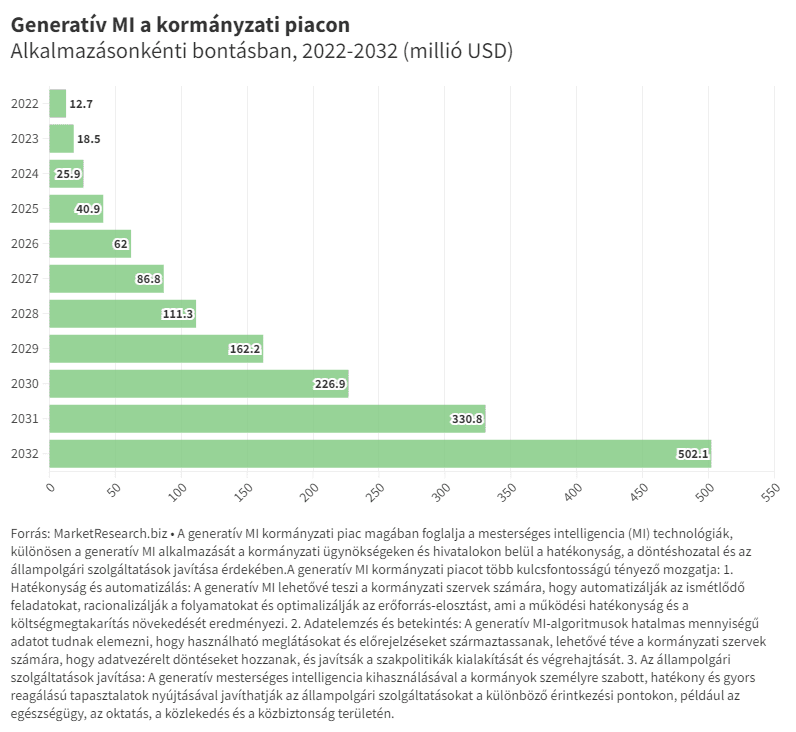
Az MI 2.0 egyik (nagyon korai stádiumban lévő) példája a Haz megoldás lehet. Ez az e-mail nyugtákat egy MI modellbe táplálja, hogy a felhasználók korábbi vásárlásai alapján közösségi feedeket hozzon létre. A modell segít a Haz-nek kiszűrni a közösségi hírfolyam szempontjából nem releváns vásárlásokat, és a hírfolyam kitöltéséhez fontos termékinformációkat keresni vagy kinyerni. Ez a tartalmi egység válik aztán a felhasználók közötti interakciók alapjává: a „lájkoktól” kezdve a barátok tulajdonában lévő termékekre való licitálásig bezárólag.
Ha ez ismerősen hangzik, az nem véletlen. Ez majdnem olyan mint a Web 1.0-ról a Web 2.0-ra való átmenet. Azaz a felhasználók számára az információk elérését lehetővé tevő alkalmazásokról az áttérést megtenni olyanokra, melyek lehetővé teszik a tartalom létrehozását és fogyasztását. A Web 2.0 lehetővé tette a többszereplős interakciókat, ahogyan azt ma a Facebookhoz hasonló közösségi hálózatokon és a piactereken láthatjuk. Bár a hálózati hatások már évtizedek óta léteznek a technológia világában (a telefon megjelenésétől kezdve), a Web 2.0 a rájuk épülő vállalatok számának jelentős bővüléséhez és következésképpen értékteremtéshez vezetett.







