
Legutóbb nyolc Big Data analitikai eszközt hasonlítottam össze aszerint, hogy melyik miben lehet segítségére egy-egy vállalkozás jobban teljesítésének kialakításában. Most használati esetekkel mutatom be, hogy egy adatmérnök milyen fogalmakkal, definíciókkal találkozik – és ezeket miként fordíthatja egy-egy vállalkozás javára.
Tapasztalatom szerint fogalmakat példákon keresztül lehet a legjobban leírni és bemutatni. Így most ezen elv követése mellett próbálom bemutatni a leggyakoribb fogalmakat, amivel adattranszformáció, adattárolás stb. témák olvasása közben találkozhatunk.

Business Scenario & Data Architecture (Üzleti célok és adat architektúra)
Képzeljük el: jövőre egy új webáruház (mikroszkópokat forgalmazó) keres meg minket új adat infrastruktúrájának kialakításával! Az online értékesítésben az adatok állnak a középpontban, rengeteg keletkezik belőlük, sokkal több, mint 20 vagy 30 évvel ezelőtt. A webáruházak e rengeteg adat feldolgozásával – adatközpontú megközelítéssel – próbálják javítani a teljesítményt; a logisztikai tevékenységet, illetve értékesítést.
Próbáljuk meg most mi ezen elképzelt eset alapján kialakítani egy adat architektúrát webáruházunk támogatására az alábbi három rétegre alapozva:
- Data Lake (Adattó),
- Data Warehouse (Adattárház),
- Data Mart.
Data Lake (Adattó)
Egy Adattó tárolóként szolgál a különböző forrásokból előállított nyers és strukturálatlan adatok számára a webáruház ökoszisztémán belül, például: offline értékesítés adatai (napi látogatók a boltban, napi értékesítés), közösségi média hírcsatornák, jegyértékesítés, marketing eseményekre regisztrált partnerek, logisztikai kiszolgálás sebessége, stb.
Mindenféle adat tárolható a konszolidált adat tárolóban: strukturálatlan (hang, videó, képek), félig strukturált (JSON, XML) és strukturált (CSV, Parquet, AVRO).
Az első kihívással máris szembesülünk: minden adatot egyetlen helyre kell integrálunk. Megoldásként kötegelt munkákat hozunk létre különböző forrásból származó rekordok kinyerésére és felkészülünk az adatok valós idejű továbbítására (és így arra, hogy ezzel nagyon alacsony – akár real-time – késleltetésű adataink is elérhetőek lesznek).
Mint adatmérnök, legyünk tisztában azzal, hogy az integrálandó rendszereink listái nagyon eltérőek lehetnek, mindegyik más protokollt és/vagy interfészt fog támogatni: SFTP, MQTT, REST API, GraphQL stb.
Nem leszünk egyedül ebben az adatgyűjtésben; számtalan adatintegrációs eszköz áll rendelkezésre a piacon, amelyekkel egy helyen konfigurálhatók és karbantarthatók a feldolgozási folyamatok (például: Fivetran, Hevo, Informatica, Twilio Segment, Stitch, Talend stb.). Ezekkel az eszközökkel elkerüljük, hogy a ütemezett szkriptek tömegeire támaszkodjunk, az eszközök segítenek nekünk az adatok egyszerűsítésében, automatizálásában.

1.ábra – Adattó és adatintegráció
Data Warehouse (Adattárház)
Miután meghatároztuk és létrehoztuk az összes integrálandó adatfolyamot, most az adatok sokféleségét dolgozzuk fel az adattárházunkban.
Az Adattárház az Adattóból származó feldolgozott adatok tisztítására, strukturálására és tárolására szolgál, így strukturált, nagy teljesítményű környezetet biztosít az elemzésekhez és a jelentésekhez.
Ebben a szakaszban már nem az adatok feldolgozásáról van szó , egyre inkább az üzleti felhasználási esetekre kell összpontosítani. Meg kell fontolnunk, hogy az adatokat miként használják fel kollégáink, akik rendszeresen frissített, strukturált adatkészleteket dolgoznak:
- Sales: értékesítési adatok alapján prediktív modellek segítségével konverzió javítása.
- Marketing: ügyfelek viselkedését vizsgálják megpróválva csökkenteni az általános lemorzsolódást.
- Stratégia és trend áttekintése: a múltbeli értékesítési adatok, akciók a trendek hatásának megértésére használják.
- KPI: logisztikai költségek csökkentése, szállítási határidő növelése, profitábilisabb terméket válassza a vevő.
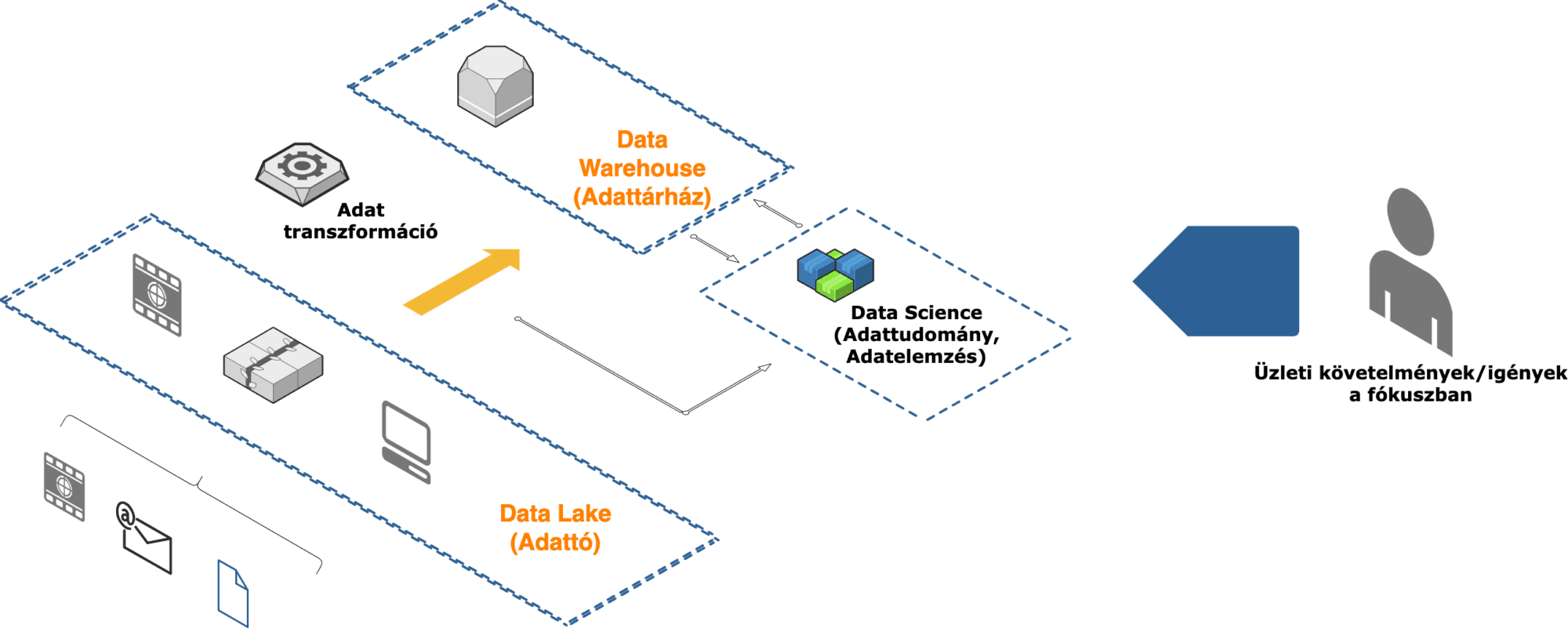
2.Ábra – Data Warehouse és adatátalakítás
Számos adatfolyamunk lesz az adatok átalakítására és normalizálására.
Az adatintegrációhoz hasonlóan rengeteg termék áll rendelkezésre a piacon az adatfolyamok egyszerűsítésére és hatékony kezelésére. Ezek az eszközök leegyszerűsíthetik adatfolyamatainkat, csökkentve a működési költségeket és növelve a fejlesztések hatékonyságát (például: Apache Airflow, Azure Data Factory, DBT, Google DataForm stb.).
Data Marts
Vékony a határvonal az Adattárház és a Data Marts között. Az adatoknak hozzáférhetőnek kell lenniük, és az adott üzleti egységek követelményeihez kell igazodniuk. Azaz adatmodellek az üzleti igények köré épülnek.
A Data Marts az Adattárházak speciális részhalmazai, amelyek meghatározott üzleti funkciókra összpontosítanak.
- Felhasználói performancia Mart: Vizsgáljuk a belépési, kilépési pontokat, vásárlási folyamat lemorzsolódását, kosárba tétel/kosár törlés eseményeket. A felhasználói performancia csapat ezen adatokra építve kér fejlesztéseket a webáruházban próbálva ezzel javítani a meghatározott KPI-kat.
- Közösségi performancia Mart: A marketingcsapat elemzi a közösségi média adatait, a rajongói felméréseket és a értékeléseket, hogy megértse a preferenciákat. A marketingcsapat ezeket az adatokat személyre szabott marketingstratégiák, árucikkek fejlesztésére és fejlesztésére használja fel.
- Pénzügyi analitika Mart: A pénzügyi csapatnak is szüksége van adatokra. Fontos, hogy nyomon kövessék a költségvetési határokat, a bevételeket és általában a költségek áttekintését.
Gyakran követelmény annak biztosítása, hogy az érzékeny adatok csak az arra jogosult csapatok számára legyenek hozzáférhetők. Például a Felhasználókat elemző csapatnak szüksége lehet kizárólagos hozzáférésre a felhasználói információkhoz, és szükségük van arra, hogy az adatokat egy adott adatmodell segítségével elemezzék. Előfordulhat azonban, hogy nem kapnak engedélyt (vagy nem érdeklődnek) a pénzügyi jelentések elérésében.
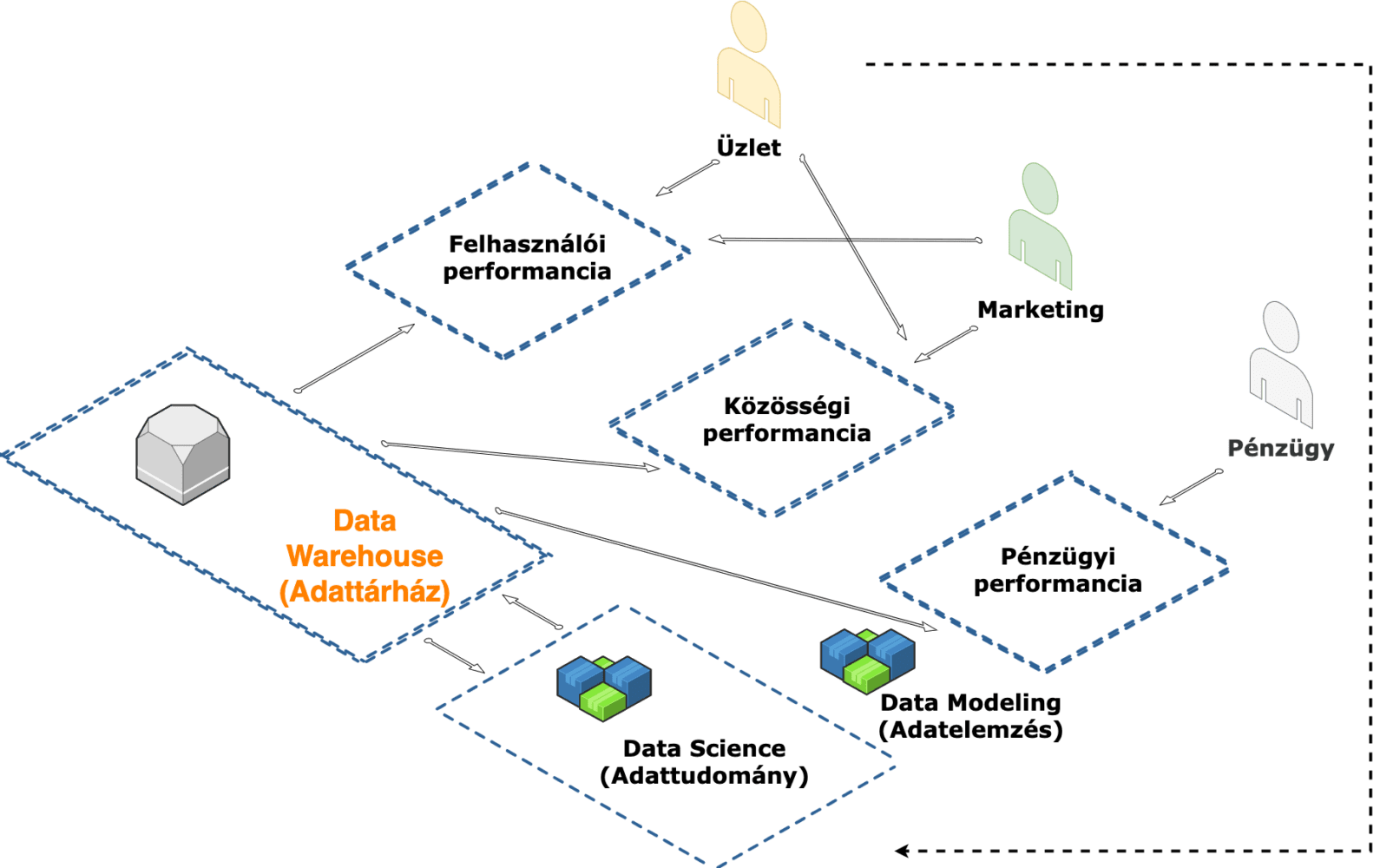
3.ábra – Data Mart és adatmodellezés
Réteges adat architektúra lehetővé teszi az adatmérnök, illetve a csapat számára, hogy kihasználja az adatok ismeretében az webáruház teljesítményének optimalizálását, stratégiai döntéshozatalhoz és továbbfejlesztett marketing eredményekhez, kampányokhoz stb.
![]()
4.ábra – kialakított adat architektúra áttekintő modellje
Ez minden? – Egy adatmérnök konklúziója
Ez még egyáltalán nem minden! Sőt: alig karcoltuk meg egy adatarchitektúra felületét. Valószínűleg több száz további integrációs pontot is figyelembe kell vennünk. Ráadásul nem részleteztük az adatok átalakítását, adat modellezését. Egyáltalán nem foglalkoztunk az Data Science-el, amely valószínűleg megérne legalább egy további, saját cikket. És bizony: ugyanez igaz az adatkezelésre és az adatbiztonságra is.
Az adatmérnökök szinte korlátlan számú integrációs eszközzel és változatos adat platformokkal dolgoznak, amelyek célja a fent említett rétegek – egy vagy több – lefedése (például: AWS Redshift, Azure Synapse, Databricks, Google BigQuery, Snowflake stb.), adatvizualizációs eszközök (például: Looker, PowerBI, Tableau.)
Az adatrétegek gyakran kombinálhatók egymással, néha egyetlen platformon. Az adat platformok és eszközök napról napra emelik a lécet és csökkentik a hiányosságokat (ha minden jól megy), új funkciókat termelnek ki. Mik merülhetnek fel:
- Mindig kell egy adattó? Attól függ mit szeretnénk.
- Mindig a lehető leggyorsabban tárolni kell az adatokat (más néven streaming és valós idejű feldolgozás)? Attól függ mit szeretnénk. Mi az üzleti felhasználók adat frissítési követelménye és elvárása?
- Mindig harmadik féltől származó eszközökre kell hagyatkoznia az adatfolyamok kezeléséhez? Attól függ mit szeretnénk.
- <Írj ide bármilyen kérdést ami eszedbe jut>? Attól függ mit szeretnénk.
Minden esetben a követelmények, üzleti igények, pénzügyi lehetőségeink befolyásolják, hogy az adatmérnök milyen eszközöket használjon. Így mindig más-más megoldás lesz a tökéletesen testhezálló. Fontos, hogy ne ugorjunk bele amíg nem dolgoztuk ki a részleteket és nem tudjuk, hogy mi a cél.
Linkek egy helyen:
- Adattípusok: JSON, XML, CSV, Apache Parquet, Apache Avro
- Interface-ek: MQTT, REST API, GraphQL
- Adatintegráció: Fivetran, Hevo, Informatica, Twilio Segment, Stich, Talend
- Adatfolyamok: Apache Airflow, Azure Data Factory, DBT, Google Dataform
- Adat platformok: AWS Redshift, Azure Synapse, Databricks, Google BigQuery, Snowflake







